An ideal IT infrastructure design must guarantee that critical applications and systems are always available. It should withstand hardware failure, network outage, power issue or any other disaster. When critical applications and systems fail, it could mean downtime, lost productivity, loss revenue and tarnish reputation to the company. Both high availability and disaster recovery are vital for these reasons.
High Availability
A High Availability system is one that is designed to be available 99.999% of the time, or as close to it as possible by eliminating single points of failure. Usually this means configuring a failover system that can handle the same workloads as the primary system. High available system can recover from server or component failure automatically.
For hardware equipment, High Availability is achieved by designing the system with redundant components for servers, storage system, network, power supplies and cooling system that will avoid the rest of the system to fail if that component failed.
In a virtualized environment, High Availability is attained by creating a pool of virtual machines and associated resources within a cluster. When a given host or virtual machine fails, it is restarted on another VM within the cluster.
HA only works if you have systems in place to detect failures and redirect workloads, whether at the server level or the physical component level. A simple High Availability design is hosting two application servers with HA solution between them. If the application service goes down, the HA solution automatically fail-over to the second server.
Disaster Recovery
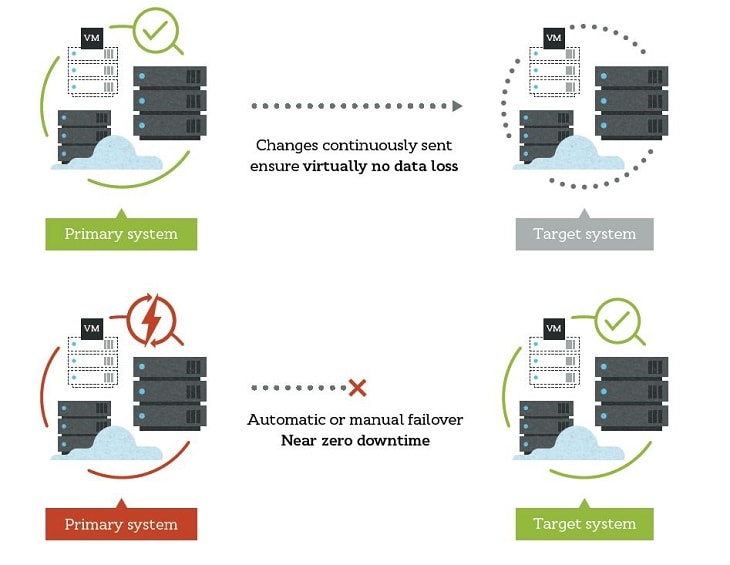
Disaster Recovery does include High Availability in the technology design. It consists of a complete plan to recover critical business systems and normal operations at an alternate site in the event of a catastrophic natural disasters such as typhoon, flood, fire or a cyberattack, or any other cause of significant downtime. It is an entirely separate physical infrastructure site with a 1:1 replacement for every critical infrastructure component, or at least as many as required to restore the most essential business functions.
A DR is configured with a designated Recovery Time Objective (RTO) and Recovery Point Objective (RPO) which represent the time it will take to restore the critical systems and the point in time before the disaster. DR platform replicates your chosen systems and data to a separate physical infrastructure. When downtime is detected, this system is turned on and your network paths are redirected. DR is generally a replacement for your entire data center, whether physical or virtual.
Protect and maintain your business. Micro Image shall provide you solution packages suitable for your High Availability and Disaster Recovery requirements. Your data protection matters to us!
![]()